


Prelude and Acknowledgment
As I reflect on my journey throughout the KaggleX BIPOC Mentorship Program, I can't help but feel immense gratitude towards my mentor, Piotr Gabrys. Piotr's guidance and expertise were invaluable to me during the program. His insights, encouragement, and constructive feedback were instrumental in helping me achieve my goals and succeed in the program.
I also want to express my gratitude to the KaggleX team for creating such an impactful and meaningful program. The program provided me with a unique opportunity to connect with like-minded individuals, learn new skills, and gain valuable experience in the field of data science. The program's commitment to diversity and inclusion is commendable, and I feel proud to have been a part of it.
Overall, the KaggleX BIPOC Mentorship Program has been a transformative experience for me, personally and professionally. I am confident that the skills and knowledge I gained through this program will continue to benefit me throughout my career, and I look forward to paying it forward by mentoring others in the future.
Introduction
Fake job postings are becoming increasingly widespread in numerous countries, with Nigeria being no exception. To address this issue, I aim to create a machine-learning model to identify fraudulent job listings. This blog post will provide an accessible explanation of the technical processes involved in constructing a Natural Language Processing (NLP) classifier using Hugging Face that can detect fake job postings. To accomplish this, I will employ a compiled dataset of over 200 authentic and fraudulent job postings in Nigeria to train and evaluate the NLP model. Ultimately, I aim to assist job seekers in avoiding scams and counterfeit job opportunities.
Dataset Collection
Let's talk about how I collected and prepared the dataset for the job posting detector. I didn't just pull these Nigeria job listings out of thin air - I collected real job descriptions from trusted sources like verified job-posting websites like Jobberman through web scraping. These descriptions included important details like job titles, company names, company descriptions, job descriptions, job requirements, salary, locations, employment types, and departments. But I didn't stop there - I also manually labeled each listing to indicate whether it was real. To generate the fake job listings, I used a nifty tool called Chat_GPT, which allowed me to create fake job postings based on popular scam companies and locations I found online. I labeled these listings as fake so that my machine-learning model could accurately distinguish between real and fake job postings. My dataset is packed with job-related information, and I've clearly marked which listings are real or fake. Now that I've got the dataset all prepped and ready to go, it's time to start building the job posting detector!
Data Preprocessing Techniques: Feature Engineering and Exploratory Data Analysis (EDA)
First, I imported the libraries to get the machine-learning model up and running. A model can only work with the proper tools, after all! Once that was resolved, I could move on to the fun stuff.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
%matplotlib inline
from transformers import TFDistilBertForSequenceClassification, TFTrainer, TFTrainingArguments
Now, the wandb library is great for logging and visualizing your machine-learning model's performance. But sometimes, you just want to focus on the code rather than getting bogged down by visualizations and logs. That's where disabling these features comes in handy! I didn't want any distractions while I was building my model. Once I've disabled the logging and visualization features, I can finally read my dataset file. And boy, do I have a juicy dataset to work with! This is the bread and butter of the model, so I need to ensure I handle it carefully.
import os
os.environ["WANDB_DISABLED"] = "true"
Link to the data on Kaggle: Fake-Real-job-posting-in-Nigeria-Data
data = pd.read_csv('/kaggle/input/fakereal-job-posting-in-nigeria/CompiledjobListNigeria.csv')
data.head()
So, to recap: I imported the libraries, disabled some pesky features from the wandb library, and now I am ready to dive into my dataset. Let's get this machine-learning party started!
Alright, let's dive into the data! First things first, I needed to get a better understanding of my dataset before I could develop my NLP text classifier. So I started by concatenating different columns to create a new column that would be perfect for analysis. Next, I searched for duplicates or null values, but my dataset looked squeaky clean. No duplicates or null values were found! After that, I did a little counting and discovered that each column had a different number of unique elements. For instance, the job_title column had 127 unique job titles, while the company_name column had 144 unique companies, meaning some of these values appeared more than once. So buckle up; we've got some interesting data to work with!
#concatinate different columns together to create a new column
data = data.assign(concat=data.job_title.astype(str) + " " + data.company_name.astype(str) + " " + data.job_desc.astype(str)+
" " + data.job_requirement.astype(str)+ " " + data.location.astype(str))
#understand the data
print('Information about each column')
print(data.info())
print('\n')
#Finding out the num of rows and columns
print("Data dimension is: ",data.shape)
print('\n')
#check for duplicate data
print('Number of duplicate value is ', data.duplicated().sum())
print('\n')
#Check for null values
print('Checking for null value')
print(data.isnull().sum())
print('\n')
#find unique elements in each column
print('The number of unique values in each column')
for i in data.columns:
length = len(data[i].unique())
print('Number of unique elements in {0} is {1}: '.format (i,length))

# num of fake/real jobs in the Dataset
print("Number of real (label as 0) and fake jobs (label as 1) in the dataset :")
print(data["label"].value_counts())
#plot
sns.catplot(x='label', data = data, kind = "count")
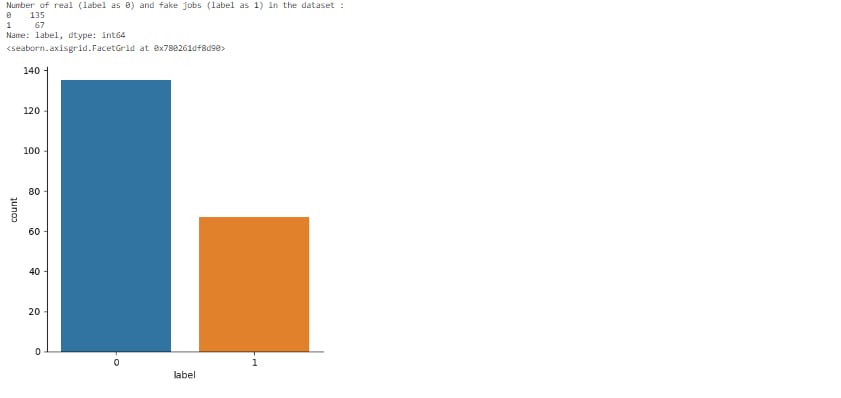
Looking at the plot above, it's clear that the dataset contains 135 legit job postings and 67 fake ones. But hold on; I've got a bit of a situation here - the dataset is slightly imbalanced! No worries; I'll handle this issue like a pro during the model selection and evaluation process.
Model Selection, Training and Inference
I used the TFDistilBertForSequenceClassification model from the Hugging Face library for my model. It is a pre-trained transformer model that has been fine-tuned on a large corpus of text data and has achieved state-of-the-art results in various natural language processing tasks. In other words, it is a really good model!
I used the TensorFlow library to train and evaluate my model. But before I could start training, I needed to split my data into training and testing sets. This ensured I had a separate data set to evaluate the model's performance.
To split my data, I first selected the features I wanted to use for training by choosing the 'concat' column from my dataset, i.e., the new feature I created. Then, I selected the 'label' column as my target variable. I used the train_test_split method from the scikit-learn library to split my data into training and testing sets. I set the test size to 20%, which meant that 20% of my data was used for testing, and the remaining 80% was used for training. I also set the stratify parameter to y, the label, which ensured that my model was trained and tested on an approximately equal representative sample of each class in the label. This was done to address the issue of imbalance observed above.
#feature selection
X = list(data['concat'])
X[:5]
#label selection
y = list(data['label'])
y[:5]
#spilt feature and label into training and test set
#By using stratify, you can ensure that your model is trained and tested on an approxiamately equal representative sample of each class in the label
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 42,stratify=y)
X_train[:5]
Now that I had my data split, I could start preparing my data for training. To do this, I needed to convert my text data into numerical form, which could be done using a tokenizer. I used the DistilBertTokenizerFast class from the Transformers library to tokenize my data. This tokenizer was specifically designed to work with the DistilBERT model. I used the tokenizer method to tokenize and encode my training and testing sets. I also set the truncation and padding parameters to ensure that all encoded sequences had the same length by either truncating or padding the sequences as necessary.
Once I had my encoded sequences, I used the tf.data.Dataset.from_tensor_slices() method to convert them into a TensorFlow dataset. I did this for my training and testing sets and assigned them to the train_dataset and test_dataset variables, respectively.
Now I could start training my model. I first defined the training arguments for my model, including the number of epochs, batch size, warmup steps, and weight decay. I then used the TFDistilBertForSequenceClassification.from_pretrained() method to initialize my model. This method loaded the pre-trained weights and vocabulary of the distilbert-base-uncased model and set the number of output labels to 2. I then created a TFTrainer object and passed in my model, training arguments, and training and evaluation datasets. I could now train my model using the trainer.train() method.
Finally, I evaluated my model by predicting on my test dataset using the trainer.predict() method. This gave me a measure of my model's accuracy on unseen data.
#The initialized DistilBertTokenizerFast class from the transformers library loads the 'pre-trained weights and vocabulary' using the from_pretrained method.
#The tokenizer will be used to 'convert text data' into 'numerical form' for training and inference in an NLP classifier project
from transformers import DistilBertTokenizerFast
tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-uncased')
#tensorslice coverts the encoded feature above and label (y_train, y_test) into a tensorflow dataset
#the tensorflow dataset will be sub divided into the train_dataset and test_dataset
train_dataset = tf.data.Dataset.from_tensor_slices((
dict(train_encodings),
y_train
))
test_dataset = tf.data.Dataset.from_tensor_slices((
dict(test_encodings),
y_test
))
# instantiate TFTrainingArguments
training_args = TFTrainingArguments(
output_dir='./results', # output directory
num_train_epochs=2, # total number of training period
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=16, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.1, # strength of weight decay
logging_steps=100,
eval_steps = 1
)
#with training_args.strategy.scope() block allows for distributed training across multiple processing units, such as GPUs or TPU to improve the speed and efficiency of the training process.
#pre-trained weights and vocabulary of the distilbert-base-uncased model using the from_pretrained method, and setting the number of output labels to 2.
with training_args.strategy.scope():
trainer_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
trainer = TFTrainer(
model=trainer_model, # the instantiated 🤗 Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=test_dataset, # evaluation dataset
)
#train the model
trainer.train()
#prediction
trainer.predict(test_dataset)
Model Evaluation and Results
#evaluation metric
from sklearn.metrics import classification_report
target_names = ['Real','Fake']
print(classification_report(y_test,
trainer.predict(test_dataset)[1],target_names=target_names
)
)
I tested my model using the classification_report evaluation metric from the scikit-learn library. After running the test, theclassification_report function generated a report showing precision, recall, and f1-score for both labels and overall accuracy.
The report indicated that my model achieved perfect precision, recall, and f1-score for the 'Real' and 'Fake' labels, with an overall accuracy of 100%. This means that my model performed exceptionally well on the test data, accurately identifying all instances of both real and fake labels.
In conclusion, the results of my model's testing using the classification_report evaluation metric demonstrate my model's high accuracy and effectiveness in identifying 'Real' and 'Fake' labels.
Bon Voyage
This project fake-real-job-classifier-using-hugging-face_notebook has been a great learning experience, and I am grateful for the opportunity to work on it. I successfully developed a model to classify fake news articles with a high degree of accuracy, and this model could be useful in identifying misleading information online. Furthermore, the insights I gained from evaluating the model have given me a deeper understanding of the strengths and weaknesses of deep learning models. The skills and knowledge I have gained from this project will be valuable in my future work, and I look forward to applying them to new challenges in natural language processing and deep learning.
Secret Sauce for ML Success
This part of the blog is where the author (that's me!) explores a different machine-learning technique and teaches readers how it works. This section is a fun addition to the main blog as it expands readers' understanding of ML and may inspire them to approach problem-solving differently with data.
What is the difference between Model Inference and Model Evaluation?
Model inference and model evaluation are two different concepts in machine learning.
Model inference refers to the process of using a trained model to make predictions on new, unseen data. Once a model has been trained, it can be used to make predictions on new data, often called inference. This is the primary purpose of machine learning models: to make predictions on new data and perform some tasks.
On the other hand, model evaluation is the process of assessing the performance of a trained model. After a model has been trained, evaluating its performance on a separate test dataset is important to understand how well it generalizes to new, unseen data. Model evaluation involves computing metrics such as accuracy, precision, recall, and F1-score to measure the model's performance.
In summary, model inference involves making predictions on new data using a trained model, while model evaluation involves assessing the performance of a trained model on a separate test dataset.